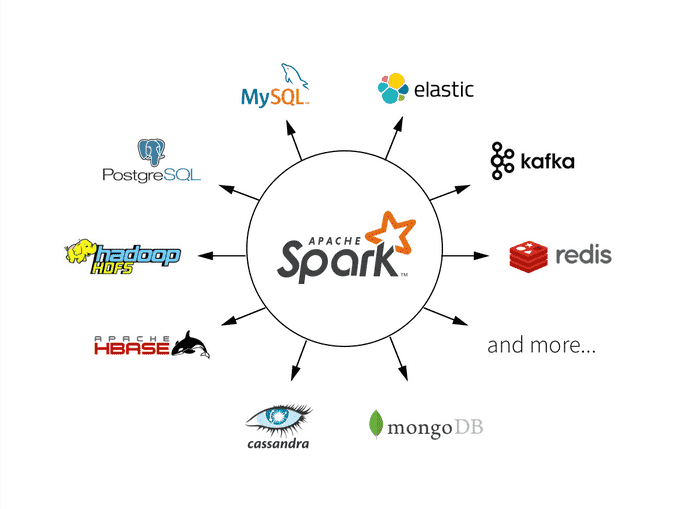
This definition explains Apache Spark which is an open source parallel process computational framework primarily used for data engineering and analytics. But later maintained by Apache Software Foundation from 2013 till date.
 Apache Spark What Is Spark
Apache Spark What Is Spark
Spark is an Apache project advertised as lightning fast cluster computing.

What is apache spark used for. Apache Spark is an open-source parallel processing framework that supports in-memory processing to boost the performance of applications that analyze big data. Spark provides a faster and more general data processing platform. Apache Spark Spark is an open source data-processing engine for large data sets.
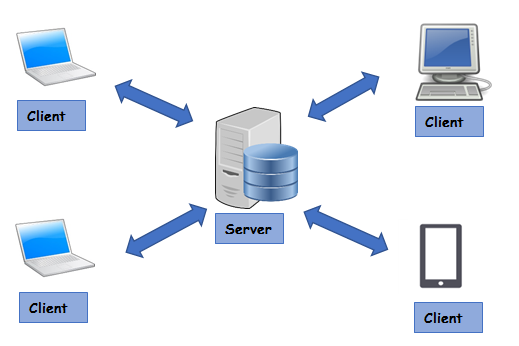
A cluster in this context refers to a group of nodes. Apache Spark is a powerful tool for all kinds of big data projects. It was introduced by UC Berkeleys AMP Lab in 2009 as a distributed computing system.
Search database or list for free. Its also responsible for executing parallel operations in a cluster. Azure Synapse makes it easy to create and configure a serverless Apache Spark pool in Azure.
Apache Spark is an open-source distributed processing system used for big data workloads. What is Apache Spark. It utilizes in-memory caching and optimized query execution for fast queries against data of any size.
It has a thriving open-source community and is the most active Apache project at the moment. Sparks analytics engine processes data 10 to 100 times faster than. Big data solutions are designed to handle data that is too large or complex for traditional databases.
Apache Spark is an open-source distributed processing system used for big data workloads. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations which includes interactive queries and stream processing. Simply put Spark is a fast and general engine for large-scale data processing.
It can handle up to petabytes thats millions of gigabytes of data and manage up to thousands of physical or virtual machines. It is designed to deliver the computational speed scalability and programmability required for Big Dataspecifically for streaming data graph data machine learning and artificial intelligence AI applications. It tries to keep all data in memory only writing to the disk s if there is not sufficient memory.
EasyLearning On its website Apache Spark is explained as a fast and general e n gine for large-scale data processing. Ad Used repo Ditch Witch drill rigs. Search database or list for free.
Apache Spark is a lightning-fast cluster computing technology designed for fast computation. Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. But still there are certain recommendations that you should keep in mind if you want to take advantage of.
Some distinctive features includ e its use of memory and focus on easy development. Apache Spark is a unified analytics engine for big data processing with built-in modules for streaming SQL machine learning and graph processing. Apache Spark is a general-purpose cluster computing framework.
It utilizes in-memory caching and optimized query execution for fast analytic queries against data of any size. Spark is a lighting fast computing engine designed for faster processing of large size of data. Apache Spark is an open-source engine for analyzing and processing big data.
SearchDataManagement Search the TechTarget Network. Apache Spark in Azure Synapse Analytics is one of Microsofts implementations of Apache Spark in the cloud. Spark lets you run programs up to 100x faster in memory or 10x faster on disk than Hadoop.
A Spark application has a driver program which runs the users main function. Apache Spark defined Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets and can also distribute data processing tasks across multiple. Ad Used repo Ditch Witch drill rigs.