It was developed at the University of California and then later offered to the Apache Software Foundation. What is Spark in Big Data.
 Apache Spark Perangkat Lunak Analisis Terpadu Untuk Big Data
Apache Spark Perangkat Lunak Analisis Terpadu Untuk Big Data
Apache Spark is a distributed and open-source processing system.
Spark big data. Be it in agriculture research manufacturing you name it and there this technology is widely used. RRDs are fault tolerant which means they are able to recover the data lost in case any of the workers fail. It utilizes in-memory caching and optimized query execution for fast analytic queries against data of any size.
An Example to Predict Customer Churn. Ad Unlimited access to Big Data market reports on 180 countries. It was originally developed at UC Berkeley in 2009.
Basically Spark is a framework - in the same way that Hadoop is - which provides a number of inter-connected platforms systems and standards for Big Data projects. Spark is a unified one-stop-shop for working with Big Data Spark is designed to support a wide range of data analytics tasks ranging from simple data loading and SQL queries to machine learning and streaming computation over the same computing engine and with a consistent set of APIs. Download Reports from 10000 trusted sources with ReportLinker.
It is used for the workloads of Big data. Spark can be used with a Hadoop environment standalone or in the cloud. Apache Spark is a lightning-fast unified analytics engine for big data and machine learning.
Berkeley in 2009 Apache Spark has become one of the key big data distributed processing frameworks in the world. It provides development APIs in Java Scala Python and R and supports code reuse across multiple workloadsbatch processing interactive. Advance your data skills by mastering Apache Spark.
Apache Spark is a unified analytics engine for big data processing with built-in modules for streaming SQL machine learning and graph processing. Apache Spark is an open-source framework for processing huge volumes of data big data with speed and simplicity. Ad Unlimited access to Big Data market reports on 180 countries.
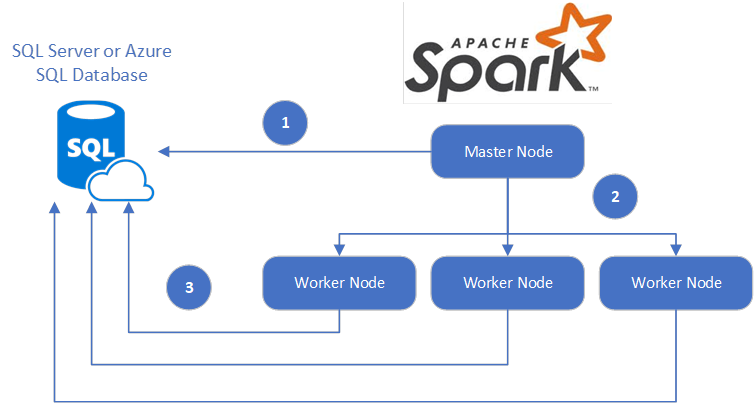
When using Spark our Big Data is parallelized using Resilient Distributed Datasets RDDs. Big Data is a new term that is used widely in every section of society. Big Data with PySpark.
Like Hadoop Spark is open-source and under the wing of the Apache Software Foundation. From cleaning data to creating features and implementing machine learning models youll execute end-to-end workflows with Spark. Well go on to cover the basics of Spark a functionally-oriented framework for big data processing in Scala.
Download Reports from 10000 trusted sources with ReportLinker. A Tutorial Using Spark for Big Data. Building up the desire to extract the most relevant information from huge amounts of data can lead u s to what.
Essentially open-source means the code can be freely used by anyone. Big Data with Spark in Google Colab. Aug 8 2019 10 min read.
Apache Spark is an open-source distributed processing system used for big data workloads. Well end the first week by exercising what we learned about Spark by immediately getting our hands dirty analyzing a real-world data set. Using the Spark Python API PySpark you will leverage parallel computation with large datasets and get ready for high-performance machine learning.
Big Data is a field that treats ways to analyze systematically extract information from or otherwise deal with datasets that are too large or complex to be dealt with by traditional data processing applications. From its humble beginnings in the AMPLab at UC. Apache Spark has become arguably the most popular tool for analyzing large data sets.
It is simply a general and fast engine for much large-scale processing of data. It was originally developed at UC Berkeley in 2009. It is suitable for analytics applications based on big data.
As my capstone project for Udacitys Data Science Nanodegree Ill demonstrate the use of Spark for scalable data manipulation and machine learning. The largest open source project in data processing. Spark utilizes optimized query execution and in-memory caching for rapid queries across any size of data.
RDDs are Apache Sparks most basic abstraction which takes our original data and divides it across different clusters workers.
 Apache Spark For Big Data Analytics Algoworks
Apache Spark For Big Data Analytics Algoworks
 Apache Spark Vs Hadoop Mapreduce Choosing The Right Big Data Framework Skywell Software
Apache Spark Vs Hadoop Mapreduce Choosing The Right Big Data Framework Skywell Software
 Apache Spark Apache Hadoop Big Data Scala Apache Http Server Png 1656x776px Apache Spark Apache Hadoop
Apache Spark Apache Hadoop Big Data Scala Apache Http Server Png 1656x776px Apache Spark Apache Hadoop
 Apache Spark Unified Analytics Engine For Big Data
Apache Spark Unified Analytics Engine For Big Data
 Hadoop Vs Spark Choosing The Right Big Data Software Big Data Path
Hadoop Vs Spark Choosing The Right Big Data Software Big Data Path
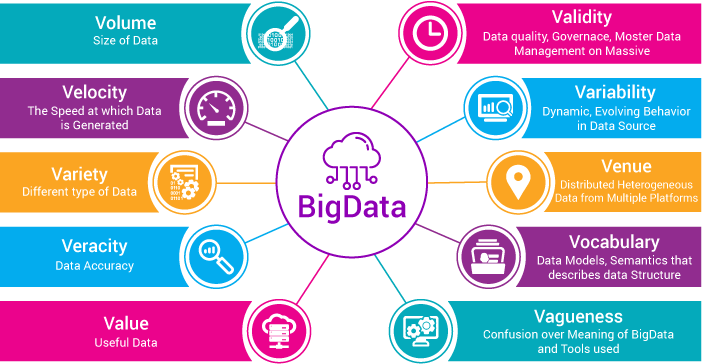 Big Data Analysis Spark And Hadoop By Pier Paolo Ippolito Towards Data Science
Big Data Analysis Spark And Hadoop By Pier Paolo Ippolito Towards Data Science
 Rdds Are The New Bytecode Of Apache Spark Apache Spark Spark Apache
Rdds Are The New Bytecode Of Apache Spark Apache Spark Spark Apache
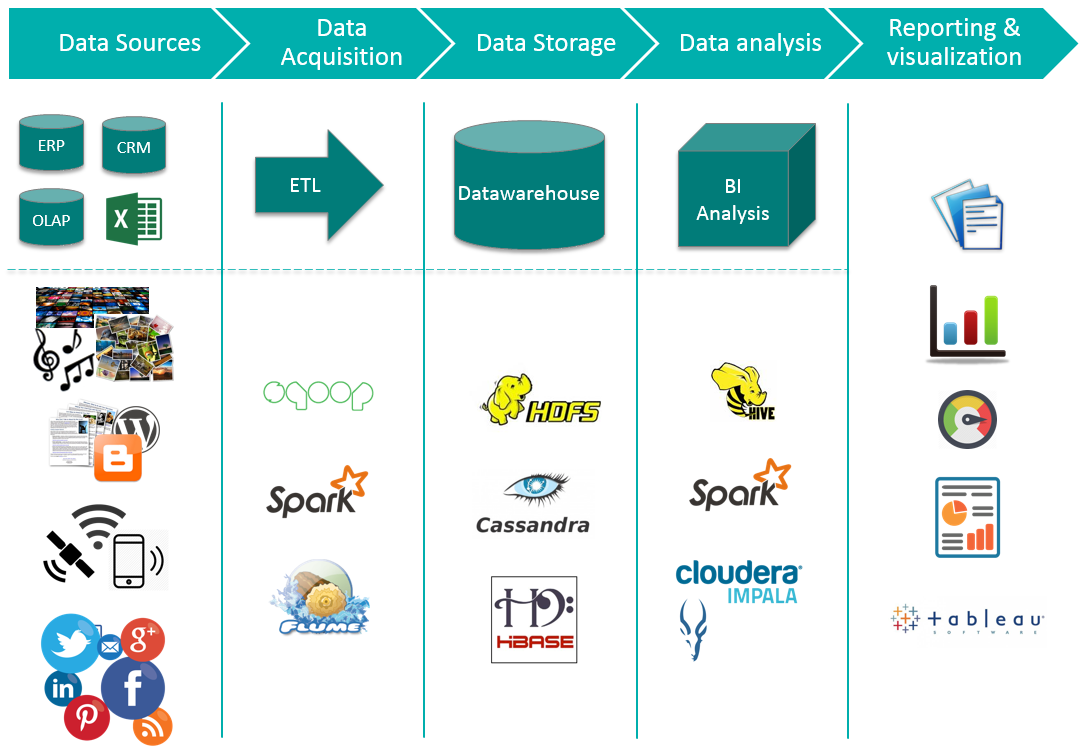 Big Data Ecosystem Spark And Tableau
Big Data Ecosystem Spark And Tableau
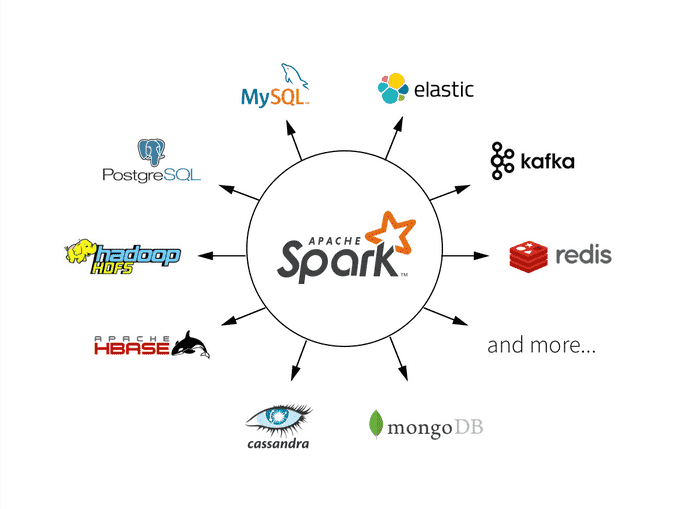 Apache Spark What Is Spark
Apache Spark What Is Spark
Big Data Analytics With Java And Python Using Cloud Dataproc Google S Fully Managed Spark And Hadoop Service By Gary A Stafford Medium
 Apache Spark Perangkat Lunak Analisis Terpadu Untuk Big Data
Apache Spark Perangkat Lunak Analisis Terpadu Untuk Big Data
 A Beginner S Guide To Apache Spark By Dilyan Kovachev Towards Data Science
A Beginner S Guide To Apache Spark By Dilyan Kovachev Towards Data Science
 How Apache Spark Became A Dominant Force In Analytics Aim
How Apache Spark Became A Dominant Force In Analytics Aim



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.